3D scene understanding has gained significant attention due to its wide range of applications. However, existing methods for 3D scene understanding are limited to specific downstream tasks, which hinders their practicality in real-world applications. This paper presents Chat-3D, which combines the 3D visual perceptual ability of pre-trained 3D representations and the impressive reasoning and conversation capabilities of advanced LLMs to achieve the first universal dialogue systems for 3D scenes. Specifically, we align 3D representations into the feature space of LLMs, thus enabling LLMs to perceive the 3D world. Given the scarcity of 3D scene-text data, we propose a three-stage training strategy to efficiently utilize the available data for better alignment. To enhance the reasoning ability and develop a user-friendly interaction scheme, we further construct a high-quality object-centric 3D instruction dataset and design an associated object-centric prompt. Our experiments show that Chat-3D achieves an impressive ability to comprehend diverse instructions for 3D scenes, engage in intricate spatial reasoning, and incorporate external knowledge into its responses. Chat-3D achieves a 75.6% relative score compared with GPT-4 on the constructed instruction dataset. Our contributions can be summarized into three parts:
Chat-3D employs a more data-efficient three-stage training process to alleviate the scarcity of 3D-language data.
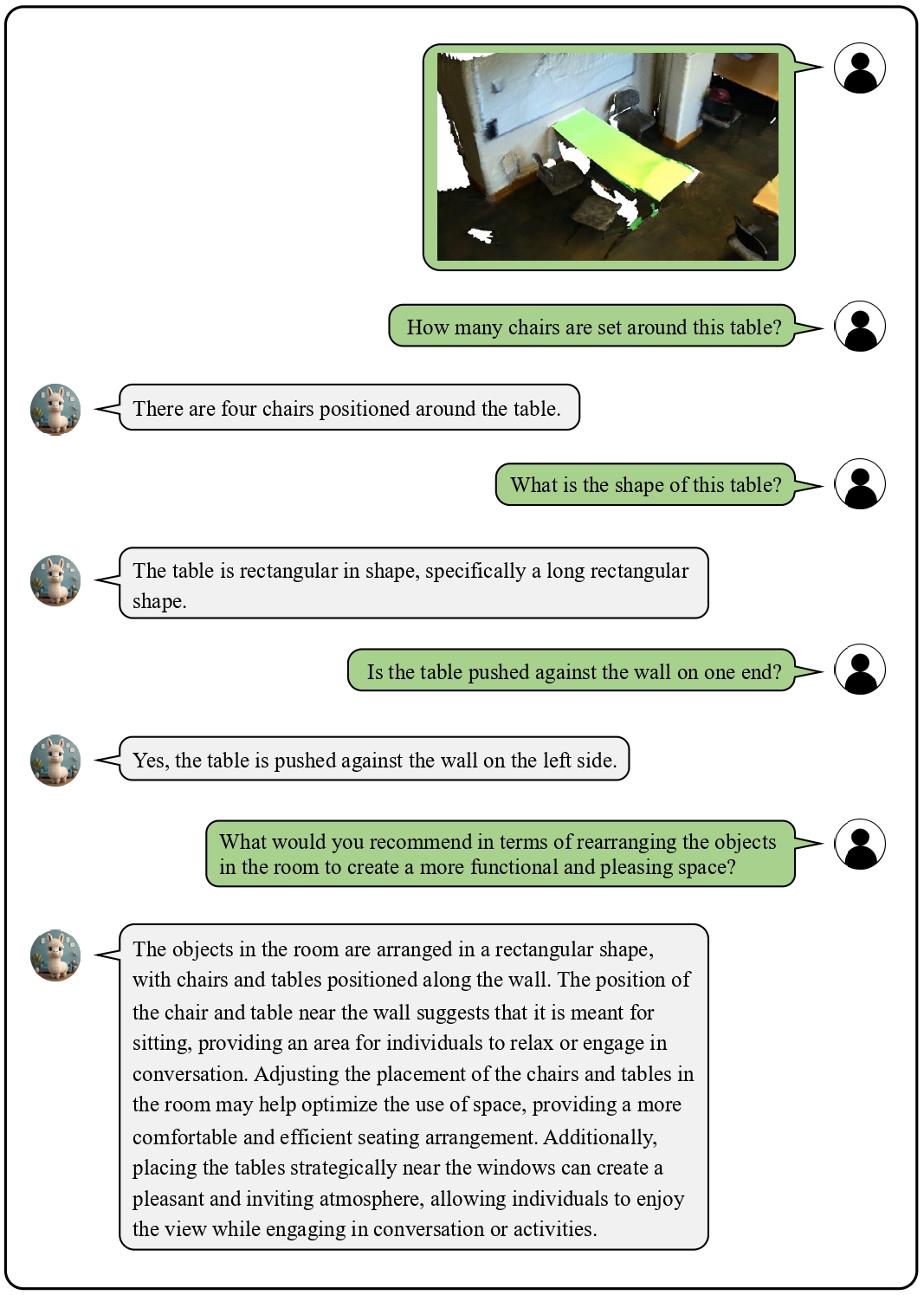
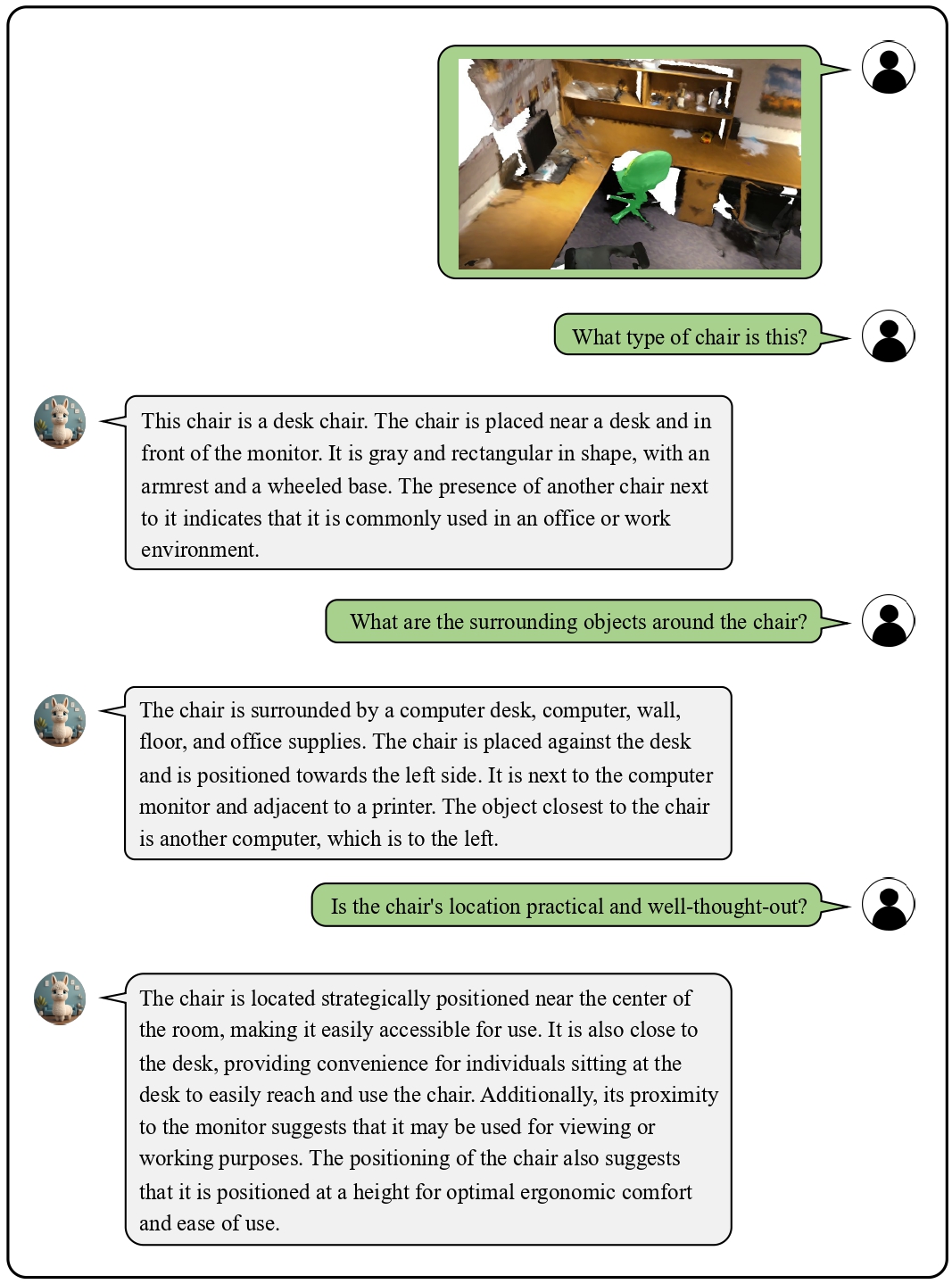
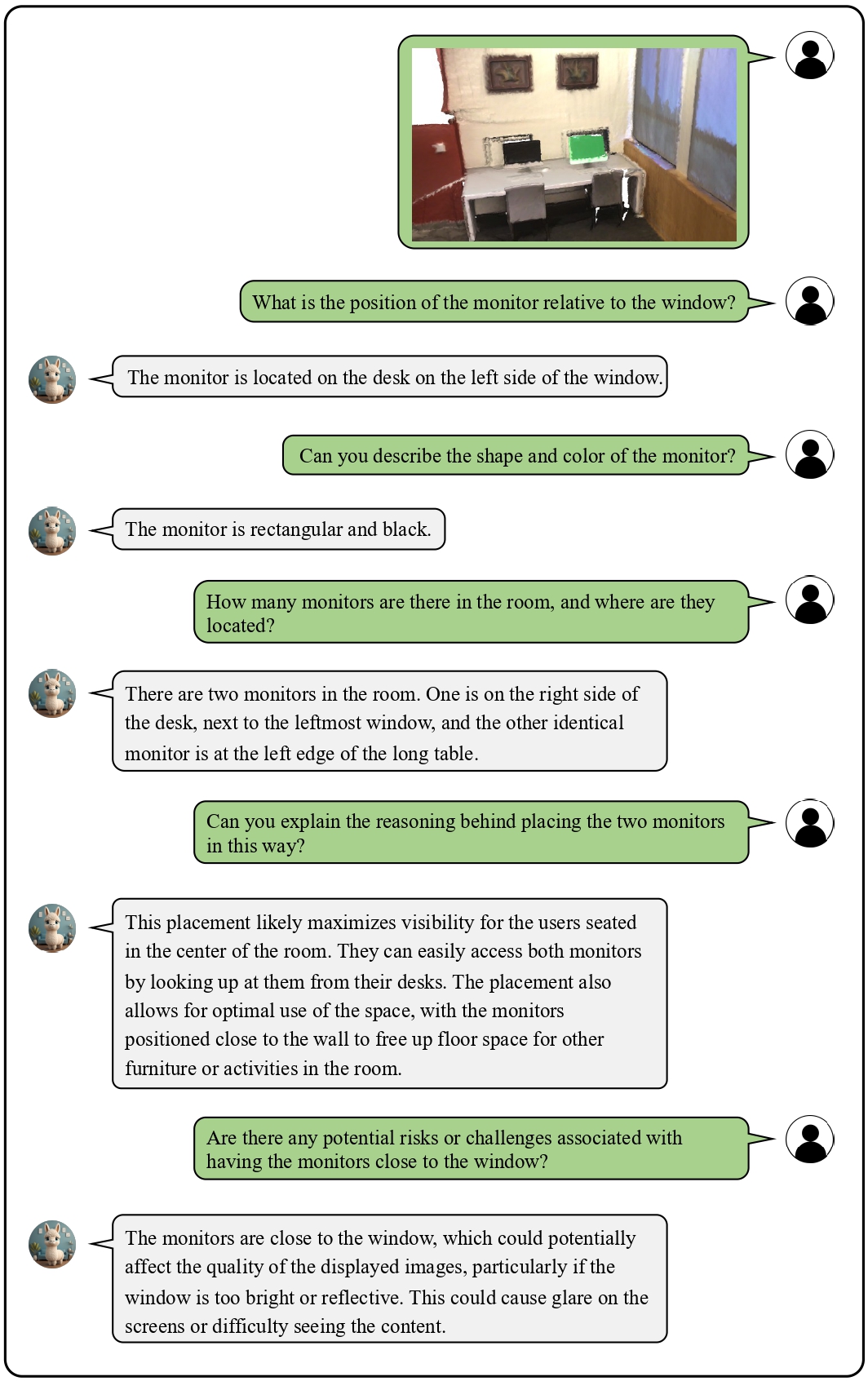
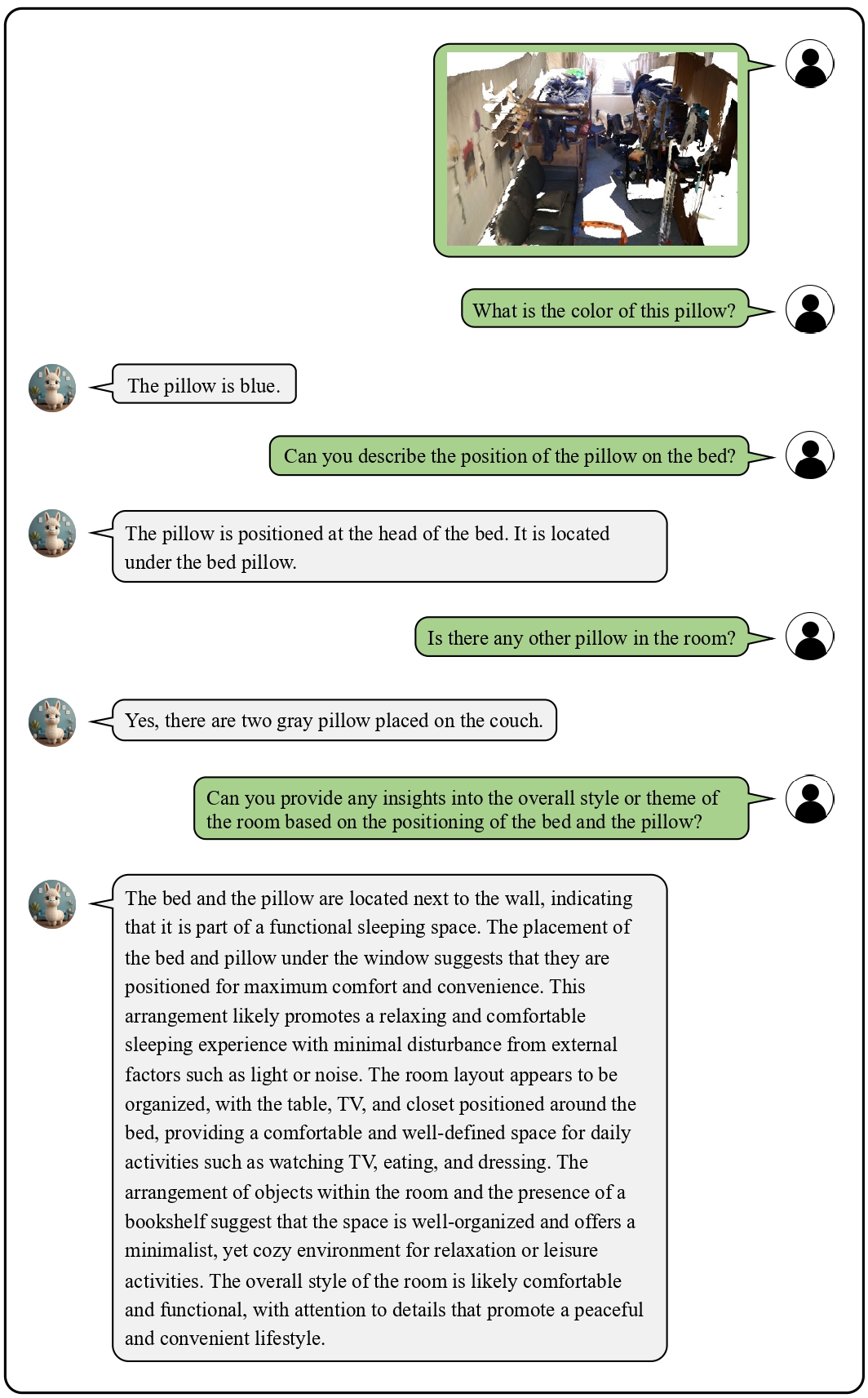
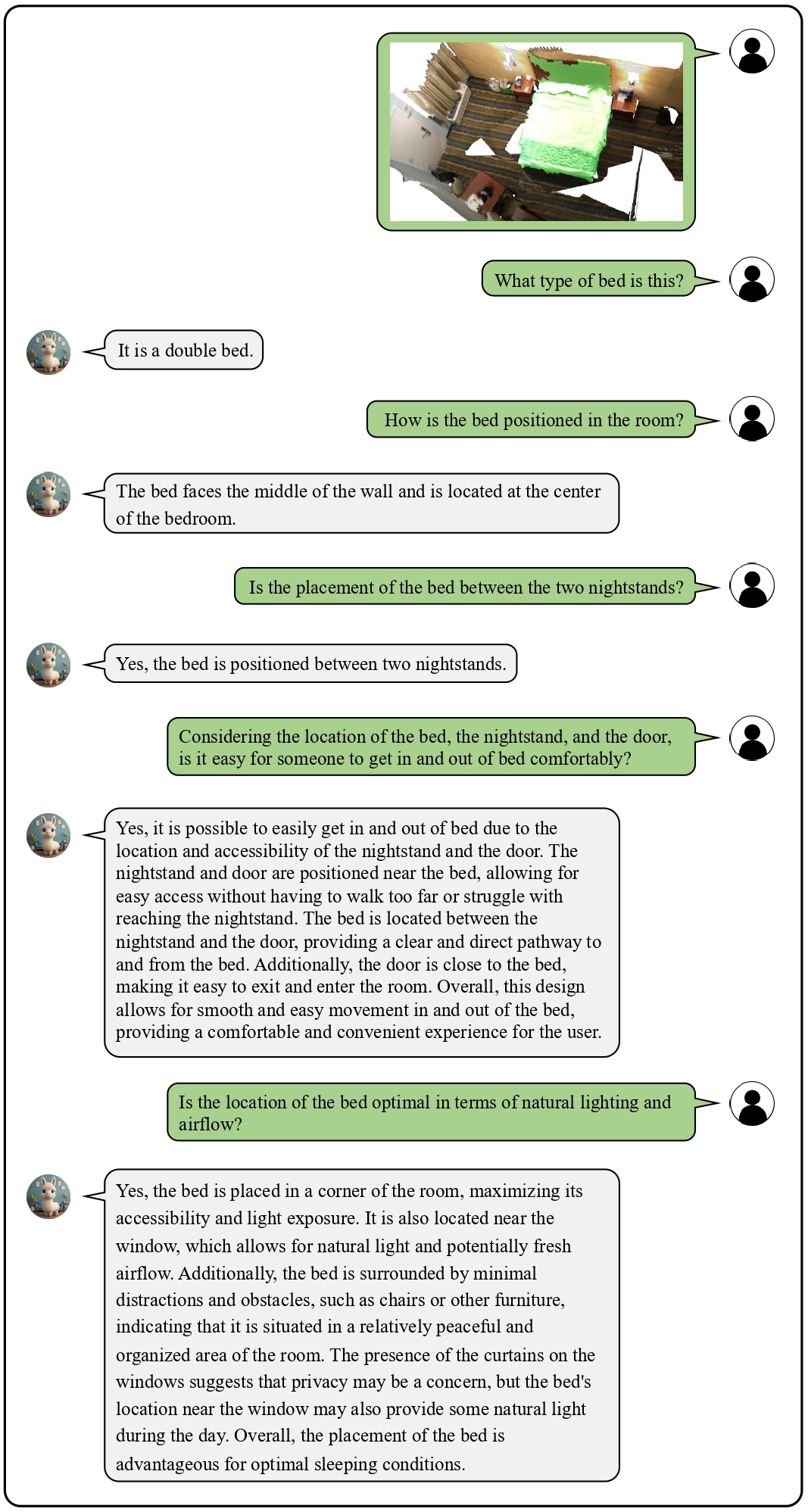
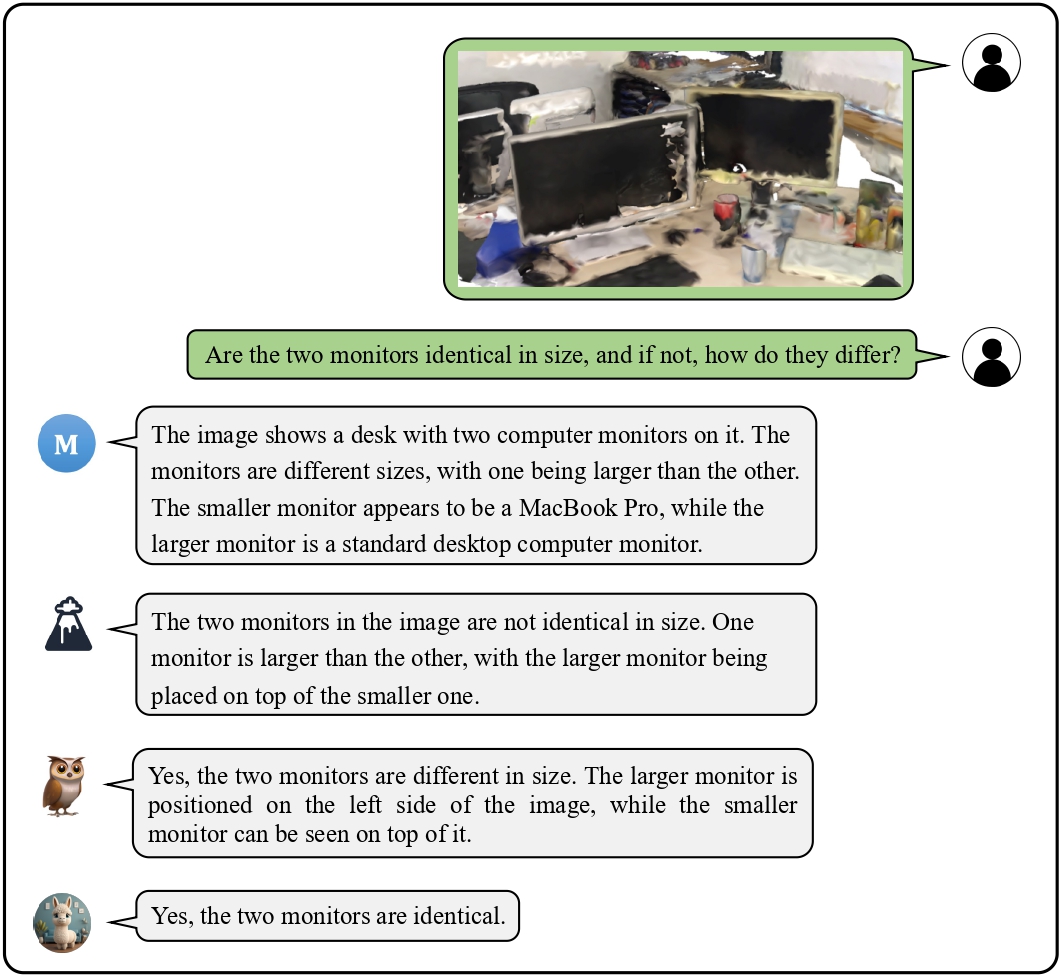
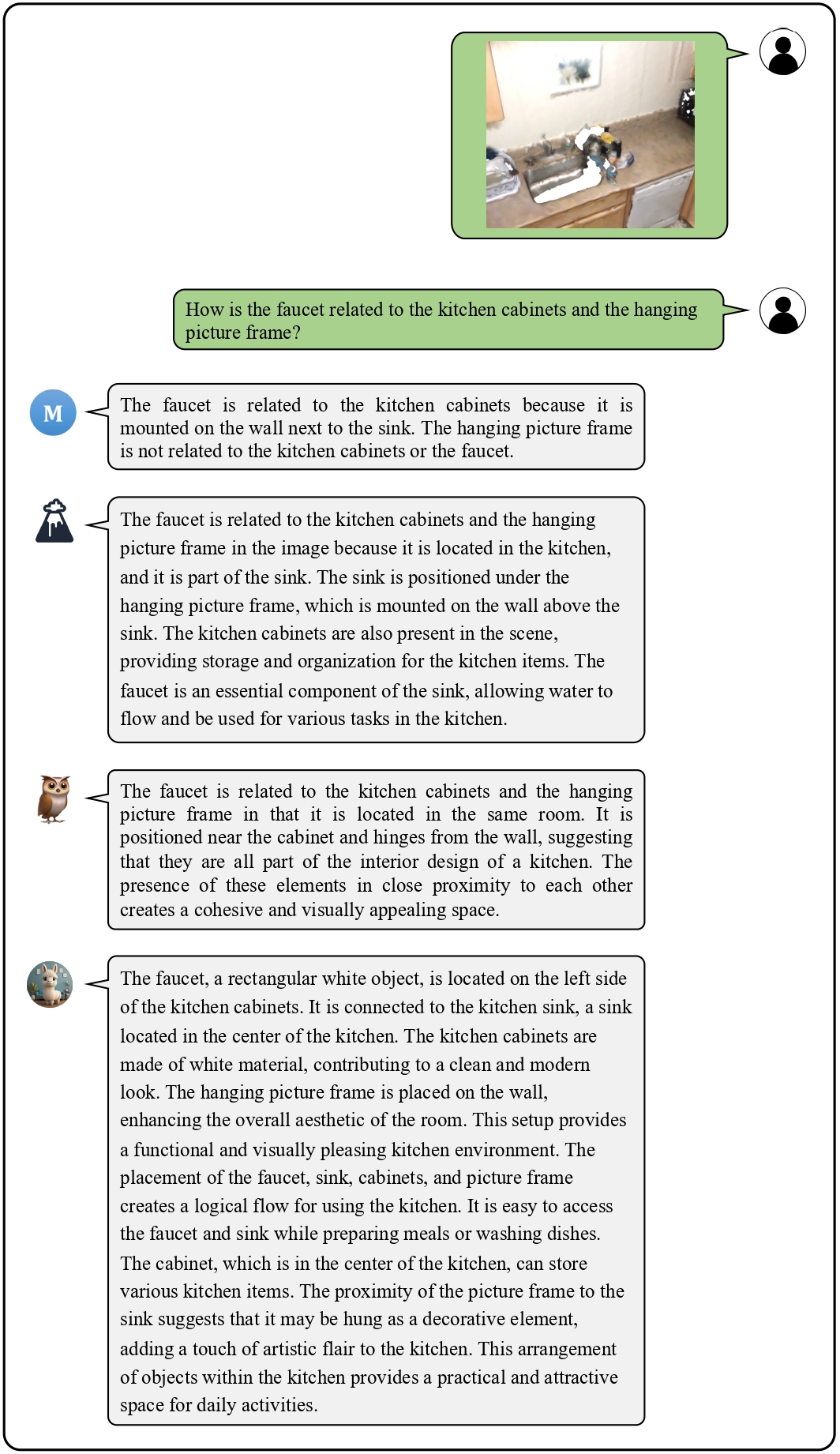
We provide visualization examples of conversations about 3D scenes with Chat-3D.
These cases highlight the powerful perceptual, reasoning, and conversational capabilities of Chat-3D for 3D scenes.

![]() Data-efficient Three-stage Training Scheme
Data-efficient Three-stage Training Scheme
![]() Examples on Universal Dialogue of 3D Scenes
Examples on Universal Dialogue of 3D Scenes



BibTeX
@misc{wang2023chat3d,
title={Chat-3D: Data-efficiently Tuning Large Language Model for Universal Dialogue of 3D Scenes},
author={Zehan Wang and Haifeng Huang and Yang Zhao and Ziang Zhang and Zhou Zhao},
year={2023},
eprint={2308.08769},
archivePrefix={arXiv},
primaryClass={cs.CV}
}